Free text analytics seems a fashionable pastime at present. The most commonly seen form in the wild might be the very basic text visualisation known as the “word cloud”. Here, for instance is the New York Times’ “most searched for terms” represented in such a cloud.
When confronted with a body of human-written text, one of the first steps for many text-related analytical techniques is tokenisation. This is the process where one decomposes the lengthy scrawlings received from a human into suitable units for data mining; for example sentences, paragraphs or words.
Here we will consider splitting text up into individual words with a view to later processing.
My (trivial) sample data is:
| ID | Free text 1 | Free text 2 | Free text 3 |
|---|---|---|---|
| 1 | Here is some | Free text! But | it needs seperating |
| 2 | Into individual words |
Can Alteryx |
Do it? |
| 3 | Of course | ALTERYX can | , no problem |
Let’s imagine I want to know how many times each word occurs. For instance, “Alteryx” appears in there twice.
Just to complicate things marginally, I’d also like to :
- remove all the “common” words that tend to dominate such analysis whilst adding little insight – “I”, “You” etc.
- ignore capitalisation: the word ALTERYX should be considered the same as Alteryx for example.
Alteryx has the tools to do a basic version of this in just a few seconds. Here’s a summary of one possible approach.
First I used an Input tool to connect to my datasource which contained the free text for parsing.
Then use a formula tool to pull all the free text fields into one single field, delimited by a delimiter of my choice. The formula is simply a concatenation:
[Free text 1] + "," + [Free text 2] + "," + [Free text 3]
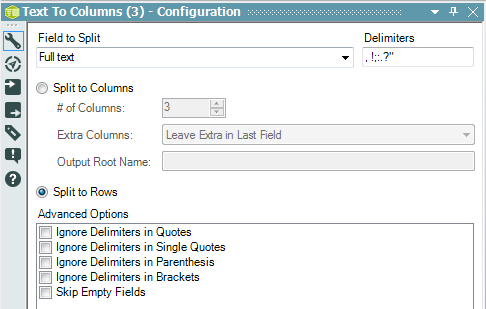
The key manipulation was then done using the “Text To Columns” tool. Two configuration options were particularly helpful here.
- Despite its name, it has a configuration option to split your text to rows, rather than columns.This is great for this type of thing because each field might contains a different, and unknown amount of words in in – and for most analytic techniques it is often easier to handle a table of unknown length than one of unknown width.
You will still be able to track which record each row originally came from as Alteryx preserves the fields that you do not split on each record, similar to how the “Transpose” tool works.
- You can enter several delimiters – and it will consider any of them independently. The list I used was
', !;:.?"', meaning I wanted to consider that a new word started or ended whenever I saw a comma, space, full stop, question mark and so on. You can add as many as you like, according to how your data is formatted. Note also the advanced options at the bottom if you want to ignore delimiters in certain circumstances.
When one runs the tool, if there are several delimiters next to each other, this will (correctly) cause rows with blank “words” to be generated. These are easily removed with a Filter tool, set to exclude any record where the text IsEmpty().
Next I wanted to remove the most common basic words, such that I don’t end up with a frequency table filled with “and” or “I” for instance. These are often called stopwords. But how to choose them?
In reality, stopwords are best defined by language and domain. Google will find you plenty based on language but you may need to edit them to suit your specific project. Here, I simply leveraged the work of the clever developers of the famous Python Natural Language Toolkit
This toolkit contains a corpus of default stopwords in several languages. The English ones can be extracted via:
from nltk.corpus import stopwords
stopwords.words('english')
which results in a list of 127 such words – I, me, my, myself etc. You can see the full current list on my spreadsheet: NLTK stopwords.
I loaded these into an Alteryx text input tool, and used a Join tool to connect the words my previous text generated (on the left side) to the words in this stopword corpus (on the right side), and took the left-hand output of the join tool.

The overall effect of this is what relational database fans might call a LEFT JOIN: an output that gives me all of the records from my processed text that do not match those in the stopword corpus.
(Alteryx has a nice “translate from SQL to Alteryx” page in the knowledgebase for people looking to recreate something they did in SQL in this new-fangled Alteryx tool).
The output of that Join tool is therefore the end result; 1 record for each word in your original text, tokenised, that is not in the list of common words. This is a useful format for carrying on to analyse in Alteryx or most other relevant tools.
If you wanted to do a quick frequency count within Alteryx for instance, you can do this in seconds by dropping in a Summarise tool that counts each record, grouping by the word itself.
You can download the full workflow shown above here.
