23andme is one of the ever-increasing number of direct to consumer DNA testing companies. You send in a vial of your spit; and they analyse parts of your genome, returning you a bunch of reports on ancestry, traits and – if you wish – health.
Their business is highly regulated, as of course it should be (and some would say it oversteps the mark a little even with that), so they are, quite rightly, legally limited as to what info they can provide back to the consumer. However, the exciting news for us data geeks is that they do allow you to download the raw data behind their analysis. This means you can dig deeper into parts of your genome that their interpretations don’t cover.
It should be said that there is considerable risk involved here, unless – or perhaps even if – you happen to be a genetics expert. The general advice on interpretation for amateurs should be to seek a professional genetic counseller before concluding anything from your DTC test – although in reality that might be easier said than done.
Whilst I might know a bit about how to play with data, I am not at all a genetics expert, so anything below must be taken with a large amount of skepticism. In fact, if you are in the perfectly legitimate camp of “best not to know” people when it comes to DNA analysis, or you feel there is any risk you won’t be able to constrain yourself to treat the innards of your genome as solely a fun piece of analysis and constrain yourself to avoid areas you don’t want to explore, it would be wise not to proceed.
Also, even as an amateur, I’m aware that the science behind a lot of the interpretation of one’s genome is in a nascent period, at best. There are many people or companies that may rather over-hype what is actually known here, perhaps even to the extent of fraud in some cases.
But if you are interested to browse your results, here is my first experience of playing with the 23andme raw data in R.
Firstly, you need to actually obtain your raw 23andme data. A obvious precondition to this is that you have purchased one of their analysis products, set up your 23andme account, and waited until they have delivered the results to you. Assuming that’s all done, you can visit this 23andme page, and press the “Download” button near the top of the screen. You’ll need to wait a while, but eventually they’ll notify you that your file is ready, and let you download a text file of results to your computer. Here, I called my example file “genome.txt”.
Once you have that, it’s time to load it into R!
The text file is in a tab-delimited format, and also contains 19 rows at the top describing the contents of the file in human-readable format. You’ll want to skip those rows before importing it into R. I used the readr package to do this, although it’s just as easy in base R.
A few notes:
- It imported more successfully if I explicitly told R the data type of each column.
- One of the column headers (i.e. the field names) starts with a # and includes spaces, which is a nuisance to deal with in R, so I renamed that right away
- I decided to import it into a dataframe called “genome_data”
library(readr)
genome_data_test <- read_tsv(".\\data_files\\genome.txt", skip = 19, col_types = cols(
`# rsid` = col_character(),
chromosome = col_character(),
position = col_integer(),
genotype = col_character())
)
genome_data_test <- rename(genome_data_test, rsid = `# rsid`)
Let’s see what we have!
head(genome_data_test)

Sidenote: the genome data I am using is a mocked-up example in the 23andme format, rather than anyone’s real genome – so don’t be surprised if you see “impossible” results shown here. Call me paranoid, but I am not sure it’s necessarily a great idea to publicly share someone’s real results online, at least without giving it careful consideration.
OK, so we have a list of your SNP call data. The rsid column is the “Reference SNP cluster ID” used to refer to a specific SNP, the chromosome and position tell you whereabouts that SNP is located, and the genotype tells you which combination of the Adenine, Thymine, Cytosine and Guanine bases you happen have in those positions.
(Again, I am not at all an expert here, so apologies for any incorrect terminology! Please feel free to let me know what I should have written 🙂 )
Now, let’s check that the import went well.
Many of the built in 23andme website reports do actaully list what SNPs they refer to. For instance, if you click on “Scientific Details” on the life-changing trait report which tells you how likely it is that you urine will smell odd to you after eating asparagus, and look for the “marker tested” section, it tells you that it’s looking at the rs4481887 SNP.
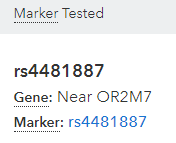
And it also tells you what bases were found there in your test results. Compare that to the data for the same person’s genome imported in R, by filtering your imported data like this:
library(dplyr) filter(genome_data_test, rsid == "rs4481887")
If the results of that match the results shown in the scientific details of your asparagus urine smell report, yay, things are going OK so far.
OK, so now your 23andme data is safely in R. But why did we do this, and what might it mean? Come back soon for part 2.

Very cool analysis! I’ve created a Python version (just because I like using Python more than R for these types of analyses) and put it on my GitHub Page: https://github.com/oconnoag/A_Deeper_Dive_Into_23andMe_Data
LikeLiked by 1 person
Thanks for the kind words! And also for sharing your analysis notebook – it was very cool to see a pandas version out there too. Hope you enjoyed digging through all that fascinating genomic data hidden behind the 23andme main reports 🙂
LikeLike