
At first glance, that question may feel like a perfect example of Betteridge’s law of headlines, the adage which states that if a headline ends in a question mark then one can usually assume the answer is no. That might well be the case here, but it doesn’t seem like it’s stopping some organisations working on products to enable just that.
Take Retorio as an example. They sell an “AI-powered” system whereby one feeds in short videos sent in by job applicants. The system claims to use an analysis of facial expressions, language, gesture and voice from the video to create a personality profile for the candidate using the Big 5 “OCEAN” scale.
The results of the personality test are then transformed into a 7-dimensional “culture fit” and a 5-dimensional “task fit” which the candidate is then scored on based on the details of the job being offered.
Personality attributes
- Openness
- Conscientiousness
- Extraversion
- Agreeableness
- Neuroticism
Culture fit
- Stability
- Competition
- Innovation
- Attention for detail
- Outcome orientation
- Team orientation
- Supportiveness
Task fit
- Dealing with others
- Task identity
- Task variety
- Autonomy
- Social relations
There are various number-based claims that, not being an HR professional, I am not really qualified to comment on, other than there being a lack of citation to published material. 70% reduced pre-screening effort, 40% better candidate funnel quality and so on. The intuition being given is that this system allows earlier, faster or cheaper ways of removing candidates from the pipeline compared to traditional methods. There are also positive claims around fairness and bias; namely that “Retorio can exclude discrimination to a degree that is almost impossible to achieve for humans”.
So how does this work? The precise details are no doubt commercial secret-sauce, but they do share some details of how their personality model works. It’s worth a read if of interest, but in summary it looks like they had around 2,500 human assessors watch a total of 12,000 video clips of other people and score them on the five OCEAN traits above. The 12k videos and resulting human-assessed personality results are fed into whichever type of “AI” model they’re using, with the intent of training a model to automatically give similar personality scores to those a human would when fed brand new videos of enthusiastic job applicants in the real world.
There’s a some data shared to establish that the results of the trained model do reflect the human ratings. Retorio reports that the average difference between the human and AI rating was about 10%, and the intraclass correlation coefficient between the human and AI results was in the range of 0.53 – 0.62. Based on typical guidelines that could be taken to indicate that there’s a “fair” or “moderate” correlation between the human and AI generated scores.
The discrimination and bias are then removed by virtue of comparing mean average differences in scores across various dimensions – from the FAQ I think it’s categories of gender, age, ethnicity and skin colour. If a systematic difference was noted in the means, e.g. if males score higher than females on a given trait, then a modifier was introduced to remove that difference.
For this to work well, I think we’d need to be confident of the following:
- That we know how to reliably translate a job specification into a desired personality type.
- That a human can reliably assess another human’s personality on the OCEAN scale via a short video clip.
- That these ratings are highly relevant to an applicant’s future performance within the proposed job opportunity
- That the model can accurately produce similar scores for both the test dataset, and future unseen video clips, specifically from self-selected job applicants.
- That applying modifiers such that the average ratings amongst different demographic groups are the same is an adequate way of “removing bias” (there being an implicit assumption here that all demographic groups do have the same average personality traits, or at least as far as it matters for this use-case). And that this modification must not remove the relevance of the score to the proposed job opportunity.
- That personality scores can be reliably and usefully transformed into the 7 culture fit and 5 task fit attributes shown above.
- That the decision to accept or reject the candidate should rightfully be influenced – at least in part – by these scores.
The company does provide some references to support some of these claims, although it would take more time than I have to follow these up to see to what extent the entire process is supported by generally accepted science. The first one I happened to click on was a perhaps rather specific article entitled “Half a minute: Predicting teacher evaluations from thin slices of nonverbal behavior and physical attractiveness.”. The second was was “Thin-slicing study of the oxytocin receptor (OXTR) gene and the evaluation and expression of the prosocial disposition“, so there’s certainly papers from multiple fields involved. Fascinating stuff, but of course more about supporting the theory involved rather than validating the outcomes of this tool. The other references can be seen on page 7 of their personality model white paper.
Whether the necessary logic is supported by science or not, some serious concerns are raised by the results that BR24 found using this tool. They tested out this system using a variety of fake job applicant video clips that they had produced in order to test the consistency of results. In a fascinating article they describe how they used actors to produce clips of supposed job applicants, in some cases deliberately altering some seemingly irrelevant attribute of the video or audio to see if it influenced the ratings the system gave.
For the system to work reliably, one naturally has to assume that 1) humans have relatively stable personalities, and 2) the AI will thus typically score the same human similarly each time if presented with several clips of them exhibiting similar behaviours. After all, if personalities genuinely vary over time so much that we would expect to see widely varying scores for several videos of the same person, then measuring them seems pointless for this use-case. People tend to stay in jobs for more time than it takes to record a short video clip.
However, as far as Retorio’s system goes, BR24’s results suggest that this might not be the case. For example, the same actress was scored as lower conscientiousness, less extroverted and less agreeable when she wore glasses.
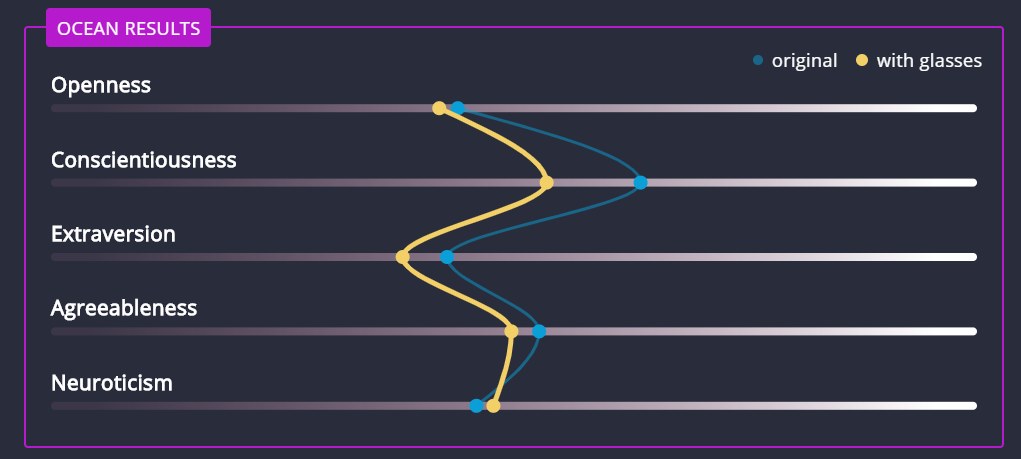
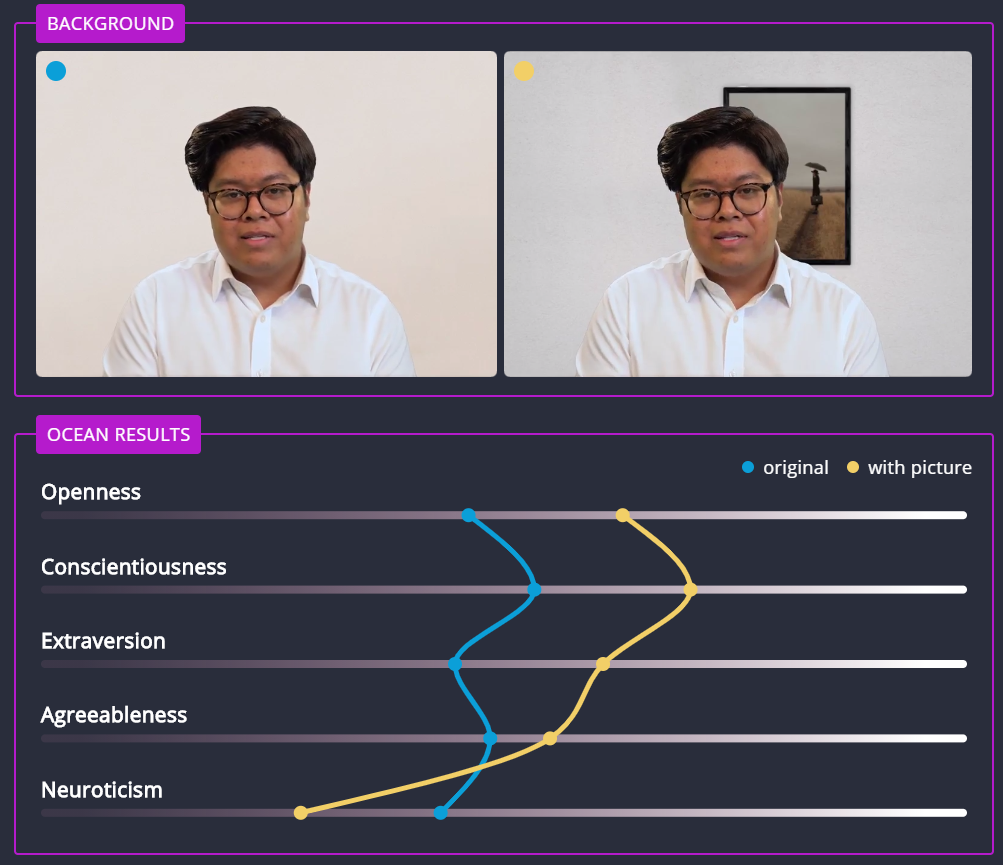
Another person was scored as more open, conscientiousness, extroverted and agreeable, but less neurotic when they happened to have a picture on the wall behind them.
One lady was scored as less open, conscientiousness, extroverted, and agreeable, but more neurotic, when the brightness of the video was turned down.

From the BR24 article, it sounds like Retorio’s defence of these findings is along the lines of that it’s quite possible that a human evaluator would rate someone differently if they had a picture on their wall. At least that’s how I interpret their words – but true or not, that doesn’t really fit with the intuition I suspect most people have that whether or not you get through to the next stage of an interview shouldn’t depend on that fact. Sure, there may or may not actually be some personality differences on average between someone who has pictures on the wall behind them when they create a video and someone who doesn’t, all other things being equal. But the important question is whether this is a reliable measure of something critical to job performance. And also whether there may be reasons, other than pure personality, as to why the person’s video had a picture on the wall or not. Certainly, the various reasons as to why one person’s video might come out brighter or darker than another person’s really don’t seem especially critical, fair or relevant to their future job ability. Even humans with the sunniest personalities don’t actually emit light.
So the AI interpretation of candidate’s videos seems, let’s say, somewhere between manipulatable and arbitrary. One common issue with certain types of AI system is that it’s not necessarily clear – even to the humans that trained it – how exactly it decides what scores to give people. There are some types of predictive model that are fairly easy to interpret – e.g. the coefficients of a linear regression model make it very obvious what affects its output. But others, such as neural nets, deep learning methods and other such fancy, fashionable and sometimes predictively powerful models are much more opaque. You can establish for sure whether it is accurately predicting things you know the answers to. But it’s harder to say what factors it’s using to do that.
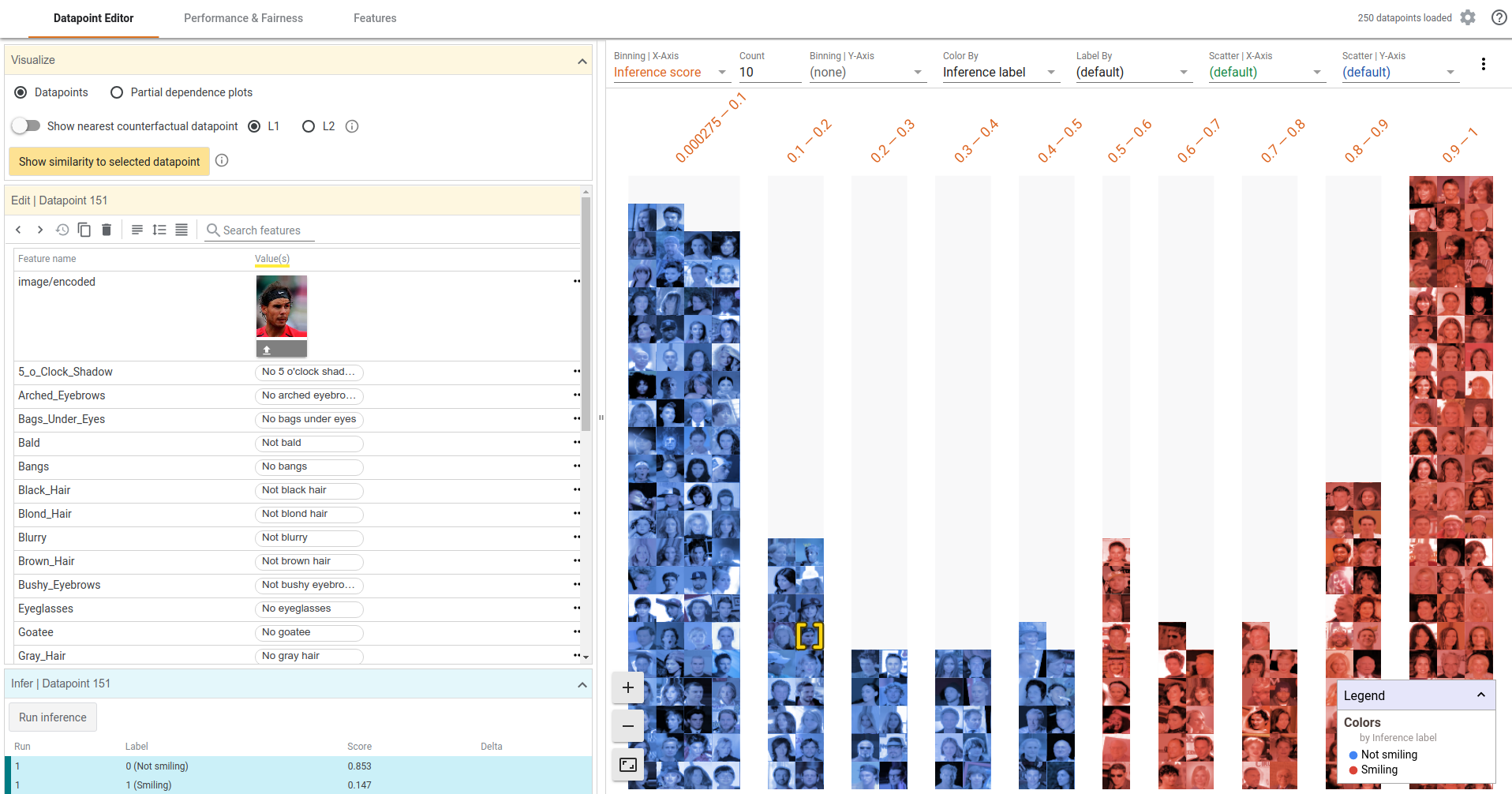
There’s ongoing research into ways of figuring out what’s inside these robotic black boxes, with some groups releasing tools to aid with this. Google offer a free one here, one of the demos of which uses a model that tries to detect which faces in photos are smiling.
However, recent history would suggest we don’t always understand what our models are doing. That’s why a model that supposedly could detect whether a person was gay or straight based on a photo of their face (!) still seems to work if you blur the faces out of the photo it uses. That’s why Amazon had to discontinue using its own “AI” based recruiting tool when it was found that behind the scenes it penalised female applicants by marking down CVs that included the word ‘women’s’ (imagine ‘I captained the women’s basketball team’) or showed that the candidate had been to certain women-only colleges.
No nefarious Amazon employee specifically coded in ‘reduce the score if you see the word women’, but the training given to the model meant that this is what its innards learned to do – basically reflecting the bias of the real world. Once this was noticed, Amazon could do similar to what Retorio claim to do and manually compensate for that particular anti-women rule – but the project was nonetheless discontinued, seemingly because it couldn’t be guaranteed that some other such as-yet-undiscovered discriminatory effect might be happening behind the scenes.
Even if the tool works perfectly as described, let’s think about what it’s doing, even ignoring the fancy robot stuff. Companies could already somewhat replicate this process without investing in Retorio type tools by giving all candidates a validated OCEAN personality test. There are several, even many free online ones – for example here, here, or elsewhere (please don’t take the links as specific recommendations!). This would be a little different in that it’s measuring the candidate’s personality as deduced from their own responses, rather than what other people who look at them would guess their personality is, but it seems a likely similar and correlated concept when one thinks about how external observer opinions are generally verified. And relatively cheap and easy to administer. For the most part, I haven’t heard of companies giving a personality test to all job applicants. It does apparently happen, but I’m not aware that it’s commonplace.
To be fair to Retorio, firstly it’s not the only company pushing such a tool, as a quick Google will confirm. They have also thought about some of the ethical concerns people may have. Apparently users of this tool are informed that a it’s voluntary scheme and that there are other methods of applying for the same job. Furthermore, the tool is designed to “support HR decision makers with data” rather than make its own decisions.
But, hey. in the real world, how are the companies that use it really going to save so much time and money if, in addition to paying for this tool, every job candidate may decide not to use it and anyway they have to employ the same amount or more HR staff in order to offer several methods of application and a capability to reliably factor whatever signal this new data provides into their decisions? I would be concerned it’s a bit like the Tesla car company releasing features (misleadingly?) called “autopilot” and “full self-driving mode“, but trying to get out of potential trouble based on the fact that technically the instructions say the driver must keep their hands on the car’s steering wheel and their eyes on the road when using them. What the customer is actually inclined to do with an “autopilot” with a “full self-driving mode” may matter more in reality than what the small print says they should do. At the end of the day, this recruitment system could be somewhat uncharitably thought of as a non-peer reviewed black box via which the candidate can manipulate their chances of employment by turning up their lights or wearing a scarf.
I suppose it’s important to remember that ine baseline that these efforts have to be measured against is “the flawed decisions human hirers make today” as opposed to “the perfect unbiased decision” – as long as we are very careful not to confuse the two.
Perhaps the difference-in-means adjustments for bias Retorio make are in fact conducive to employment equality, although there’s nothing cited to prove this. A true experiment involving hiring with and without this type of data would be fascinating, although potentially problematic on an ethical and practicality front. The technology may well get better and better at predicting how humans would evaluate each other over time. But outside of the admittedly rather critical “does it actually do what it claims to?” question, there’s a philosophically deeper question of “how do we feel about these tools if they could in fact do it perfectly?” question.
I think there’s surely some room for debate. But in the more immediate future, I wonder whether a nearer-term better use of (accurate versions of) these tools might be to generate hypotheses, leading us to introspect upon the biases and flaws of existing recruitment processes.
The average highly-liberal US west-coaster hiring tech workers may not go out of their way to discriminate against women. They may believe themselves to be an ardent feminist. But when we see that, after being fed in a bunch of past hiring decisions, Amazon’s data-sci recruitment tool learned to discriminate against women, that should give the people concerned, and the wider world in general, a big clue – as if we needed another one! – that there may be something vital to examine, regret, potentially apologise for, and certainly fix here. If we accept there are important ways in which we need to improve the recruitment process, then we don’t want to have “make the existing flawed decision-making process faster, easier and cheaper” as our primary goal.
Likewise, if we were to become confident in the Retorio model, figuring out what drives it might give us some insight in terms of how human observers judge other people’s personalities, the biases inherent to that process, how to correct for them, and perhaps to what extent contemporary measures of personality interact with job requirements. Perhaps we’re at a stage here where using statistical models to try and explain, rather than to prescribe, outcomes, is the more useful and legitimate approach.
