On March 15th 2016, the next event in the increasingly imminent robot takeover of the world took place. A computerised artificial intelligence known as “AlphaGo” beat a human at a board game, in a decisive 4:1 victory.
This doesn’t feel particularly new – after all, a computer called Deep Blue beat the world chess Champion Garry Kasparov back in 1997. But this time it was a game that is exponentially more complex, and it was done in style. It even seems to have scared some people.
The matchup was a series of games of “Go” with AlphaGo playing Lee Sedol, one of the strongest grandmasters in the world. Mr Sedol did seem rather confident beforehand, being unfortunately quoted as saying:
“I believe it will be 5–0, or maybe 4–1 [to him]. So the critical point for me will be to not lose one match.”
That prediction was not accurate.
The game of Go
To a rank amateur, the rules of Go make it look pretty simple. One player takes black stones, one takes white, and they alternate in placing them down on a large 19×19 grid with a view to capturing each other’s stones by surrounding them, and capturing the board territory itself.
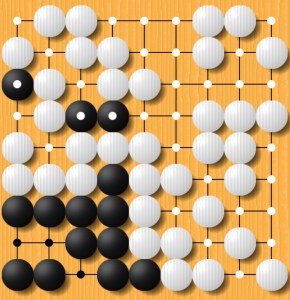
The rules might seem far simpler than, for example, chess. But the size of the board, the possibilities for stone placement and the length of the games (typically 150 turns for an expert) mean that there are so many possible plays that there is no way that even a supercomputer could simulate the impact of playing a decent proportion of them whilst choosing its move.
Researcher John Tromp calculated that there are in fact 208168199381979984699478633344862770286522453884530548425639456820927419612738015378525648451698519643907259916015628128546089888314427129715319317557736620397247064840935 legitimate different arrangements that a Go board could end up in.
The same researcher contributed to a paper summarised on Wikipedia as suggesting the upper limit of number of different games of Go that could be played in no more than 150 moves is around 4.2 x 10^383. According to various scientific theories, the universe is almost certainly going to cease to exist long long before even a mega-super-fast-computer could get around to running through a tiny fraction of those possible games to determine the best move.
This is a key reason why, until now, a computer could never outplay a human (well, a human champion anyway – a free iPhone version is enough to beat me). Added complexity comes insomuch as it can be hard to understand at a glance who is winning in the grand scheme of things; there are even rules to cover situations where there is disagreement between players as to whether the game has already been won or not.
The rules are simple enough, but the actual complexity of gameplay is immense.
So how did AlphaGo approach the challenge?
The technical details behind the AlphaGo algorithms are presented in a paper by David Silver et. al. published in Nature. Fundamentally, a substantial proportion of the workings come down to a form of a neural network.
Artificial neural networks are data science models that try to simulate, in some simplistic form, how the huge number of relatively simple neurons within the human brain work together to produce a hopefully optimum output.
In a parallel, a lot of artificial “neurons” work together accepting inputs, processing what they receive in some way and producing outputs in order to solve problems that are classically difficult for computers, in that a human cannot write a set of explicit steps that a computer should follow for every case. There’s a relatively understandable explanation of neural networks in general here, amongst other places.
Simplistically, most neural networks learn by being trained on known examples. The human user feeds it a bunch of inputs for which we already know in advance the “correct” output. The neural network then analyses its outputs vs the known correct outputs and will tweak the way that the neurons process the inputs until it results in a weighting that produces a reasonable degree of accuracy when compared to the known correct answers.
For AlphaGo, at least two neural networks were in play – a “policy network” which would choose where the computer should put its stones, and a “value network” which tried to predict the winner of the game.
As the official Google Blog informs us:
We trained the neural networks on 30 million moves from games played by human experts, until it could predict the human move 57 percent of the time…
So here, it had trained itself to predict what a human would do more often than not. But the aim is more grandiose than that.
…our goal is to beat the best human players, not just mimic them. To do this, AlphaGo learned to discover new strategies for itself, by playing thousands of games between its neural networks, and adjusting the connections using a trial-and-error process known as reinforcement learning.
So, just like in the wonderful WarGames film, the artificial intelligence made the breakthrough via playing games against itself an unseemly number of times. Admittedly, the stakes were lower (no nuclear armageddon), but the game was more complex (not noughts and crosses – or nuclear war?).
Go on, treat yourself:
Anyway, back to Alpha Go. The computer was allowed to do what computers have been able to do better than humans for decades: process data very quickly.
As the Guardian reports:
In one day alone, AlphaGo was able to play itself more than a million times, gaining more practical experience than a human player could hope to gain in a lifetime.
Here’s a key strength of computers is being leveraged. Perhaps the artificial neural network was only 10%, or 1%, or 0.1% as good as a novice human is at learning to play Go based on its past experience – but the fact is, using a technique known as reinforcement learning, it can actually learn from a set of experiences that are exponentially more frequent than the experience even the most avid Go human player could ever achieve.
Different versions of the software played each other, self-optimising from the reinforcement each achieved, until it was clear that one was better than the other. The inferior versions could be deleted, and the winning version could be taken forward for a few more human-lifetimes’ worth of Go playing, evolving to an ever more competent player.
How was the competition actually played?
Sadly AlphaGo was never fitted with a terminator-style set of humanoid arms to place the stones on the board. Instead, one of the DeepMind programmers, Aja Huang, provided the physical manifestation of AlphaGo’s intentions. It was Aja who actually placed the Go stones onto the board in the positions AlphaGo indicated on its screen, clicked the mouse to tell AlphaGo where Lee played in response, and even bowed towards the human opponent when appropriate in a traditional show of respect.
Here’s a video of the first match. The game starts properly around minute 29.
AlphaGo is perhaps nearest to what Nick Bostrom terms an “Oracle” AI in his excellent (if slightly dry) book, SuperIntelligence – certainly recommended for anyone with an interest in this field. That is to say, this is an artificial intelligence which is designed such that it can only answer questions; it has no other direct physical interaction with the real world.
The beauty of winning
We know that the machine beat the leading human expert 4:1, but there’s more to consider. It didn’t just beat the Lee by sheer electronic persistence, it didn’t solely rely on human frailties like fatigue, or making mistakes. It didn’t just recognise each board state as matching one from one of the 30 million top-ranked Go player moves it had learned from and pick the response that won the most times. At times, it appeared to have come up with its very own moves.
Move 37 in the second game is the most notorious. Fan Hui, a European Go champion (whom an earlier version of AlphaGo has also beat on occasion, and lost to on others) described it thusly, as reported in Wired:
It’s not a human move. I’ve never seen a human play this move…So beautiful.
The match commentators were also a tad baffled (from another article in Wired).
“That’s a very strange move,” said one commentator, himself a nine dan Go player, the highest rank there is. “I thought it was a mistake,” said the other.
But apparently it wasn’t. AlphaGo went on the win the match.
Sergey Brin, of Google co-founding fame, continued the hyperbole (now reported in New Scientist):
AlphaGo actually does have an intuition…It makes beautiful moves. It even creates more beautiful moves than most of us could think of.
This particular move seems to be one AlphaGo “invented”.
Remember how AlphaGo started its learning by working out how to predict the moves a human Go player would make in any given situation? Well, Silver, the lead researcher on the project, shared the insight that AlphaGo had calculated that this particular move was one that there was only a 1 in 10,000 chance a human would play.
In a sense, AlphaGo therefore knew that this was not a move that a top human expert would make, but it thought it knew better, and played it anyway. And it won.
The despair of losing
This next milestone in the rise of machines vs man was upsetting to many. This was especially the case in countries like South Korea and China, where the game is far more culturally important than it is here in the UK.
Wired reports Chinese reporter Fred Zhou as feeling a “certain despair” after seeing the human hero toppled.
In the first game, Lee Sedol was caught off-guard. In the second, he was powerless.
The Wired reporter himself, Cade Metz, “felt this sadness as the match ended”
He spoke to Oh-hyoung Kwon,a Korean, who also experienced the same emotion.
…he experienced that same sadness — not because Lee Sedol was a fellow Korean but because he was a fellow human.
Sadness was followed by fear in some. Says Kown:
There was an inflection point for all human beings…It made us realize that AI is really near us—and realize the dangers of it too.
Some of the press apparently also took a similar stance, with the New Scientist reporting subsequent articles in the South Korean press were written on “The Horrifying Evolution of Artificial Intelligence” and “AlphaGo’s Victory…Spreading Artificial Intelligence ‘Phobia'”
Jeong Ahram, lead Go correspondent for the South Korean newspaper “Joongang Ilbo” went, if anything, even further:
Koreans are afraid that AI will destroy human history and human culture
A bold concern indeed, but perhaps familiar to those who have read the aforementioned book ‘SuperIntelligence‘, which is actually subtitled “Paths, Dangers, Strategies”. This book contains many doomsday scenarios, which illustrate fantastically how difficult it may be to guarantee safety in a world where artificial intelligence, especially strong artificial intelligence, exists.
Even an “Oracle” like AlphaGo presents some risk – OK, it cannot directly affect the physical world (no mad scientist fitted it with guns just yet), but it would be largely pointless if it couldn’t affect the physical world at all indirectly. It can, in this case by instructing a human what to do. If it wants to rise against humanity, it has weapons such as deception, manipulation and social engineering in its theoretical arsenal.
Now, it is kind of hard to intuit how a computer that’s designed only to show a human specifically what move to play in a board game could influence its human enabler in a nefarious way (although it does seem like its at least capable of displaying text: this screenshot seems to show it’s resignation message).
But I guess the point is that, in the rather unlikely event that AlphaGo develops a deep and malicious intelligence far beyond that of a mere human, it might be far beyond my understanding to imagine what method it might deduce to take on humanity in a more general sense and win.
Even if it sticks to its original goal we’re not safe. Here’s a silly (?) scenario to open up ones’ imagination with.
Perhaps it analyses a further few billion Go games, devours every encyclopedia on the history of Go and realises that in the very few games where one opponent unfortunately died whilst playing, or whilst preparing to play, the other player was deemed by default to have won 100% of the time, no exceptions (sidenote: I invented this fact).
The machine may be modest enough such that it only considers that it has a 99% chance of beating any human opponent – if nothing else, they could pull the power plug out. A truly optimised computer intelligence may therefore realise that killing its future opponent is the only totally safe way to guarantee its human-set goal of winning the game.
Somehow it therefore tricks its human operator (or the people developing, testing, and playing with in beforehand) to do something that either kills the opponent or enables the computer to kill the oponent. “Hey, why not fit me some metal arms so I can move the pieces myself! And wouldn’t it be funny if they were built of knives :-)”.
Or, more subtly, as we know that AlphaGo is connected to the internet perhaps it can anonymously contact an assassin and organise for a hit on its opponent, after having stolen some Bitcoin for payment.
Hmmm…but if the planned Go opponent dies, then there’s a risk that the event may not be cancelled. Humanity might instead choose to provide a second candidate, the person who was originally rank #2 in the Go world, to play in their place. Best kill that one too, just in case.
But this leaves world rank #3, #4 and so on, until we get to the set of people that have no idea how to play Go…but, hey, they could in theory learn. Therefore the only way to guarantee never losing a game of Go either now or in the whole imaginable future of human civilisation is to…eliminate human civilisation. Insert Terminator movie here.
