
Duolingo is a popular app-and-website for learning a new (human) language, with hundreds of millions of users across the world. You tell it what language you speak and which you’d like to learn, and it teaches you via bite-size lessons, stories and audio clips with interactive tests and the like. Even as someone who hasn’t especially enjoyed learning languages in the past I find it very good, occasionally near-compulsive in its gamification of the process. Just one more 10 minute lesson and maybe you’ll be top of the league!
Part of that gamification is that you can earn achievements. One of them is the “scholar” achievement, which celebrates you learning certain milestones worth of words in your chosen language. Currently I’m working towards my level 4 scholar achievement, my aim being to learn 250 words of Spanish.

As well as the count, I was curious to know which words I’d learned. But that information didn’t seem to be available in the app. So, per standard data nerd workflow, I figured I should see if there’s a Duolingo API I could plug into and discover the answer.
As far as I can tell, there’s no official API, although there has been more than one request for something like that in various forums. This is a shame; I can imagine many ways where a personal or third-party take on monitoring your progress, what you learned, what you will learn, and so on could be interesting or useful. But hey, seems it’s not a Duolingo priority.
But no official API is OK enough for my personal needs if there’s something akin to an unofficial one. Which there is, after at least a couple of clever folk traffic-sniffed to discover how the Duolingo app works and implemented that knowledge in a duolingo-api Python package. I am in deep gratitude to Kartik Talwar and all the contributors to the latter package for figuring it out and making it freely available.
Unofficial, so I guess there are no guarantees and standard caveats apply, but my experience is that it pretty much works without headaches.
After installing it:
pip install duolingo-api
Create a Duolingo object and give it your Duolingo login details (if you dare – but you’ll have to dare if you want to use this approach!).
import duolingo
lingo = duolingo.Duolingo('your_username', 'your_password')
Obviously replacing the username and password parts of the above command with your actual username and password. Your username can be found in the profile section of the Duolingo app. It seems to often be your name followed by some randomish numbers.
Now you have that lingo object, the Python API gives you plenty of functions you can use to retrieve the data about your Duolingo progress.
For many of them, you’ll need to pass in the code corresponding to the language you’re learning, noting that you could in theory be learning several. If you don’t know the relevant code then you can retrieve the list of those that you’re currently learning using the get_languages() function
lingo.get_languages(abbreviations = True)
In my case, I’m learning Spanish, so the above gives me the code ‘es’. In the below examples you may wish to switch in the language code for whichever has taken your fancy wherever you see ‘es’ if you’re learning something other than Spanish.
In Duolingo, lessons are divided up into topics such as “School” or “Shopping”. I later learned that these are often referred to as skills. You complete several lessons in each topic, which increase your progress level with it until you reach the highest level of achievement in that topic, known as legendary.
So which topics have I learned something about so far? That’s what get_known_topics() does.
lingo.get_known_topics('es')
Which returns:
['Travel', 'Pres Tense 1', 'School', 'Shopping', 'Introduction', 'People', 'Restaurant', 'Family', 'Common Phrases']9 topics sounds pretty good, no? Maybe I’m proficient! But first let’s just check if there’s any topics I haven’t learned about yet.
lingo.get_unknown_topics('es')
['Opinions', 'Shopping 6', 'Travel 9', 'Anecdotes 2', 'Magic Land', 'Routines', 'Look it up', 'News', 'Elementary', 'Weather', 'College', 'Emotions', 'People 3', 'Clean Up', 'Memories', 'Returns', 'Hobbies', 'Fix It!', 'Commands 3', 'In Love', 'School 6', 'Neighbors', 'Schedule', 'Customs', 'Jobs', 'Requests', 'School 3', 'Shopping 4', 'Office 2', 'Vacation 3', 'Future', 'Past Tense 3', 'Blind Date', 'Requests 2', ......Oh, quite a lot then 😦 The API is returning me a simple Python list here so I can just look at the length of the list to see exactly how many topics I still need to start on.
len(lingo.get_unknown_topics('es'))
And the answer turns out to be: 234! Duolingo certainly has plenty of content. I hope to live long enough to cover it all.
Well, I’m only going to make progress through the 234 if I actually take some of these lessons. Let’s see how much effort I’ve put in today so far.
lingo.get_daily_xp_progress()
{'xp_goal': 20, 'lessons_today': [{'eventType': 'LESSON', 'xp': 15, 'skillId': '58e0a01fb9b843da4f512f586e342ac6', 'time': 1629022417}], 'xp_today': 15}OK, a distinctly unimpressive amount of learning Spanish has happened in my world so far today.
The API returned me a Python dictionary, where just by eye you can see that my experience points goal is 20, but I’ve only earned 15 so far today. And that I earned those 15 by completing a single lesson, from a skill with a rather cryptic ID of “58e0a01fb9b843da4f512f586e342ac6”.
If you don’t really see that from the above, then maybe me lazily pasting it into a random online JSON viewer will help elucidate the structure.
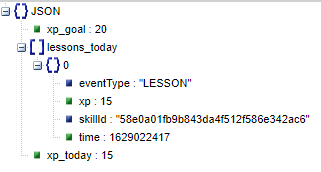
But what was the topic of that lesson? To know this, we need to look up the skill ID. One way to do this is to get a full download of the skills and our progress with them. This is similar to how we saw which topics I’d learned about above with get_known_topics(). But if we use the get_learned_skills() function we get a big list of each topic, with a whole lot of data about our progress in that skill, and the all important skill ID.
skills_list = lingo.get_learned_skills('es')
for skill in skills_list:
if(skill["id"] == '58e0a01fb9b843da4f512f586e342ac6'):
print(skill["title"])
This returns a single word, “school”. So now we know that my single lesson of the day so far was all about school.
But we can tell a lot more about each skill than simply its name with this dictionary. Checking out a couple of other attributes we can see for instance that I’ve on level 3 of the school topic (go me!) and retrieve a short list of the words the topic is going to teach us about. Note that it’s nowhere near the complete list of words that you would need to use during in this lesson, so I assume it’s more about the new or focus words the topic covers.
for skill in skills_list:
if(skill["id"] == '58e0a01fb9b843da4f512f586e342ac6'):
print(skill["title"])
print(skill["levels_finished"])
print(skill["words"])
School
3
['clase', 'examen', 'fácil', 'libro', 'bolígrafo', 'escuela', 'maestro', 'pregunta', 'estudiante', 'difícil']OK, so now we’re getting close to what was motivating me to pursue this topic; obtaining the full list of words I know. One approach might be to combine the above type of words lists from all the topics I’ve learned so far. In fact I think that’s what the get_known_words() function does:
lingo.get_known_words('es')
['hola', 'taxi', 'padre', 'buenos días', 'perdón', 'americana', 'personas', 'para', 'prestense14', 'elegante', 'el', 'España', 'me llamo', 'uno', 'azul', 'una', 'quiero', 'estados unidos', 'dos', 'pasaporte', 'casa', 'teléfono', 'gracias', 'clase', 'hotel', 'carne', 'por favor', 'prestense11', 'China', 'inteligente', 'reserva', 'bolígrafo', 'gris', 'hermana', 'verde', 'maestro', 'mesa', 'estudiante', 'tiene', 'maleta', 'mi', 'ropa', 'prestense12', 'un', 'y', 'mucho gusto', 'de', 'libro', 'madre', 'soy', 'chaqueta', 'escuela', 'camisa', 'tienda', 'hermano', 'tengo', 'tres', 'niño', 'examen', 'mujer', 'niña', 'pregunta', 'necesito', 'americano', 'sí', 'no', 'sombrero', 'la', 'difícil', 'yo', 'adiós', 'buenas noches', 'fácil', 'restaurante', 'prestense13', 'sándwich', 'carro', 'hombre', 'muy', 'vestido']But that’s a list of 80 words, which isn’t the 200+ my achievement at the top suggested. And I know I’ve seen words not in that list. “Falda”, aka skirt, is one that for some reason springs to mind. Also there’s entries like “prestense14” which seem like references to some other set of words. So I think this output might be best thought of as the words that are the main focus of the topic, rather than every word you will learn or need to know whilst completing the lesson.
To get a more comprehensive look at something more akin to the entire vocabulary I’ve learned, there exists the get_vocabulary() function, which also returns a Python dictionary full of wordy details.
vocab_dict = lingo.get_vocabulary('es')
The dictionary is slightly nested and fiddly if all you want is a list of words, but you can extract the strings of the word by looking at the word_string attribute of each item in the vocab_overview attribute.
The first word in my vocabulary?
print(vocab_dict["vocab_overview"][0]["word_string"])
This returns “tengo”, which can translate to the English “have”.
So the full list can be gotten by iterating over all of the vocab overview entries.
for v in vocab_dict["vocab_overview"]:
print(v["word_string"])
tengo
una
necesito
estudiante
escribir
problema
....I’ll spare you the other nearly 200 entries. But this time falda is on the list. I also noted that occasionally you get more of a phrase than a word. For instance, “buenas noches”, aka good night, is a single entry despite it technically being two words. But this is basically what I wanted, so I’m happy.
The vocab dictionary this comes from contains a lot of other info about each word, both about the word itself, and how your practice of it is going.
For example, here’s me looking at word 20 in the list, “leche”, which translates to milk. The entry for “skill” tells me which lesson topic it is introduced in. The attribute “pos” gives me the part of speech the word is and “gender” gives me the gender of the word, Spanish being a grammatically gendered language.
The “strength” attribute appears to be a measure of how likely Duolingo thinks I am to remember that word when I need it, with lower strengths suggesting it might be time to practice the word again. Finally here, “last_practiced” tells me when I, surprise surprise, last practiced the word. I can imagine one could use especially the latter attributes to help focus one’s efforts if the app itself wasn’t sufficient for some reason.
my_word = vocab_dict["vocab_overview"][20]
print(my_word["word_string"])
print(my_word["skill"])
print(my_word["pos"])
print(my_word["gender"])
print(my_word["strength"])
print(my_word["last_practiced"])
leche
Introduction
Noun
Feminine
0.999985
2021-08-14T17:10:45ZThere are several further attributes, these were just the main ones that caught my eye.
Eagle eyed observers who use the Duolingo website rather than the app might note that the output is quite similar to that that you get if you visit https://www.duolingo.com/words when logged into the Duolingo website. There’s the same list of words and some, albeit not all, of the metadata. Something I somehow only found out after playing with the above code. But if you had a similar objective to mine and for some reason don’t necessarily want to learn an entire coding language just to obtain a simple wordlist, there is that option. But honestly I doubt that sort of person reads this website much.
Finally for now, how did I know that leche means milk? Well, naturally because I’m an awesome Spanish speaker now thanks to completing maybe 3% of the Duolingo course 😂. But if you are even less proficient than I, the final function I wanted to mention in this library was get_translations(). Here’s how to translate “leche” from Spanish to English, without opening the app.
lingo.get_translations(['leche'], source='es', target='en')
{'leche': ['milk']}